Kozak 序列是在真核生物的mRNA中共有的(gcc)gccRccAUGG序列 。它在翻译过程的启动中扮演了重要角色。
Kozak 序列通常被认为是 GCCGCCACCATGG,其中 ATG 是起始密码子(通常是信号序列的起始)。建议使用起始密码子 ATG 上游的 GCCGCCACC 。
序列标识为(gcc)gccRccAUGG, 源自科扎克对大范围的样本(共约699种)的归纳和分析,其中:
小写字母表示此位置处最常见的碱基(仍然可以变化);
大写字母表示高度保守的碱基,例如“AUGG”序列是不变的或很少,甚至根本没有变化,唯一的例外是IUPAC的模糊码[3]。“R”这表明嘌呤(A或G)总是在这个位置上(科扎克声称A更常见)。括号内的序列((gcc))重要性不明。科扎克的研究局限于脊椎动物的一部分(例如人类,牛,猫,狗,鸡,豚鼠,仓鼠,小鼠,猪,兔,羊,非洲爪蟾)。
这个序列在mRNA分子上被核糖体识别为翻译起始位点,即蛋白质是由此开始被该mRNA分子编码的。核糖体需要此序列,或一个可能的可变形式来启动翻译。Kozak序列不应与核糖体结合位点(RBS)相混淆,后者一般为信使RNA的5’端帽或内部核糖体进入位点(IRES)。在体内(In vivo),不同的mRNA上这段区域往往不完全匹配,由一个给定的mRNA合成蛋白质的量取决于Kozak序列的强度。 这个序列中的一些核苷酸比其它的更重要:AUG是最重要的,因为它是实际的起始密码子,在对应蛋白质的N-末端编码一个甲硫氨酸。(很少地,CUG被用作起始密码子,编码亮氨酸,而不是典型的蛋氨酸作为起始。)“AUG”的A被定为1号位的话,对于一个“强”的Kozak序列,核苷酸在相对于1号核苷酸的4号位(即G所在的位置)和-3号位(即R的位点,没有号码0的位置)必须匹配一般的Kozak序列。“适中”强度的Kozak序列只有上述两个中的一个匹配,而“弱”的两个都不匹配。在-1和-2的cc并不那么保守,但有助于提升整体强度。有证据表明, 在-6位的G在翻译起始中也是重要。
共有序列的可变形式
(gcc)gccRccAUGG
AGNNAUGN
ANNAUGG
ACCAUGG
GACACCAUGG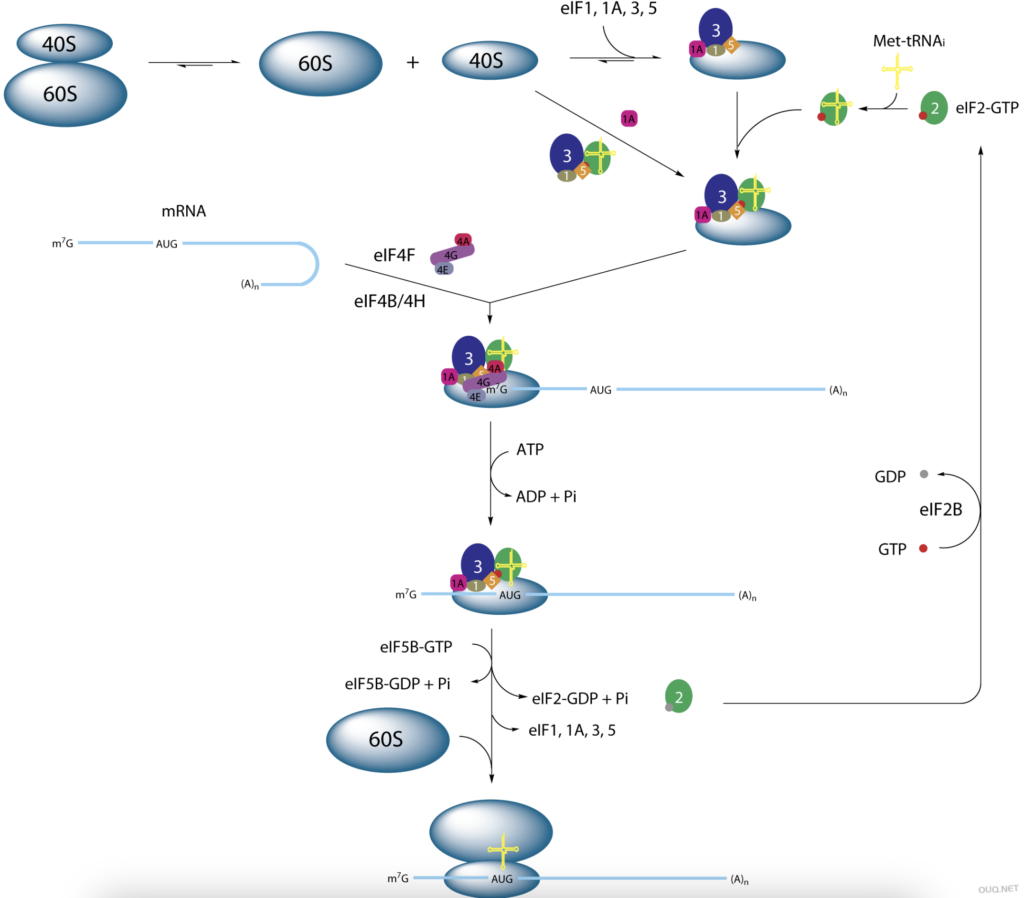
本站原创,如若转载,请注明出处:https://www.ouq.net/3240.html
 微信打赏,为服务器增加50M流量
微信打赏,为服务器增加50M流量  支付宝打赏,为服务器增加50M流量
支付宝打赏,为服务器增加50M流量