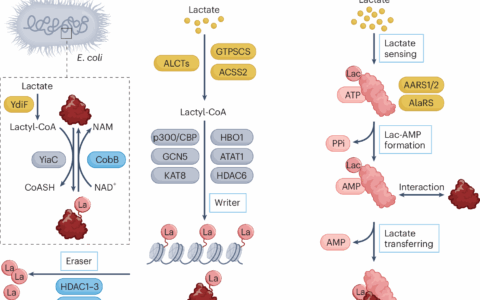
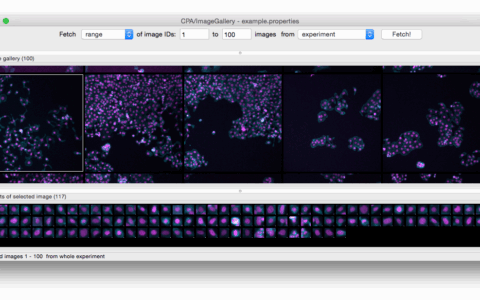
AI工具正在被滥用于生成大量结构雷同、科学严谨性存疑的生物医学研究论文,特别是那些基于开放数据集(如NHANES)的“单变量-疾病”关联研究。
? 关键信息提炼与分析
1. ? NHANES 数据集被“挖矿式”滥用
- NHANES(美国国家健康与营养检查调查)是一项长期进行的、面向公众开放的健康数据调查。
- 数据内容涵盖数千人群的健康、营养、生活方式信息,容易被AI模型快速处理。
- 2024年有超过2200篇论文使用该数据集发表,仅2025年前5个月就已有1200多篇。
⚠️ 问题:很多论文仅以单一变量(如维生素D、睡眠时间)解释复杂疾病(如抑郁症、心脏病),忽略多因多果的现实医学背景。
2. ? 模板化论文泛滥,AI嫌疑浓重
- 研究分析了2014–2024年间341篇NHANES数据驱动的研究,结果发现:
- 多数论文结构高度相似,变量选择、图表结构、结论逻辑一致;
- 169个变量与疾病建立了“统计学显著关联”,但缺乏因果机制。
- 有些变量在不同论文中互为因果:“炎症蛋白 ↔️ 牙周病 or 碳水饮食”。
研究人员认为这些论文“可能是由大型语言模型(LLMs)生成或辅助”,因为“高度公式化、易于机械生成”。
3. ? 统计分析揭露“伪显著”
- 在一个子样本(28篇将单变量与抑郁症关联的论文)中:
- 仅13篇在多重检验矫正后仍具有统计学意义;
- 剩余15篇的结果变得无效,显示出“选择性呈现”或数据“洗稿”的可能。
4. ? 数据挑选不透明,有操纵嫌疑
- 多数论文未使用完整NHANES数据集,而是选择特定年份、年龄段;
- 在14篇研究炎症蛋白的论文中,只有4篇使用完整数据集;
- 作者推测可能是为制造阳性结果或“多篇投稿”而故意拆分数据。
5. ? 与“论文工厂”相关联的风险
- 尽管该研究未直接指向“论文工厂”(Paper Mills),但NHANES的可编程性与开放性使其极易被滥用;
- AI与论文工厂结合,可能产生批量伪科学研究,污染科研文献库。
6. ? 专家建议:加强数据使用规范
- 强制研究计划注册(如预注册)或设置“数据使用前审计机制”,可限制滥用;
- 加强出版商审核机制,识别结构雷同和统计薄弱的论文;
- 科学界需更警惕“单变量—疾病”结论的泛滥,其往往不具备医学应用价值。
本文来自,本文观点不代表OUQ技术分享立场,转载请联系原作者。
 微信打赏,为服务器增加50M流量
微信打赏,为服务器增加50M流量  支付宝打赏,为服务器增加50M流量
支付宝打赏,为服务器增加50M流量